Exhaustive arithmetic from LLMs
When working on the LLM reasoning article, I explored the limits of a certain arithmetic capability of a set of LLMs.
This made me curious about how consistent llms are doing simple arithmetic. So I did a little experiment with Llama 3 8B.
I used the chat/completions endpoint of a llama.cpp server to adhere to the prompt template. The temperature was 0.
The system prompt was “Only respond with a single number.” All the user queries were of the form y+x=.
The code to replicate the experiment are in the github repository for this site.
This shows for all combinations of numbers in the range .
 I started with the range but there were only three mistakes. Those mistakes are all in the vein of , omitting the hundred.
To get more interesting results, I expanded the range.
I started with the range but there were only three mistakes. Those mistakes are all in the vein of , omitting the hundred.
To get more interesting results, I expanded the range.
Here is :
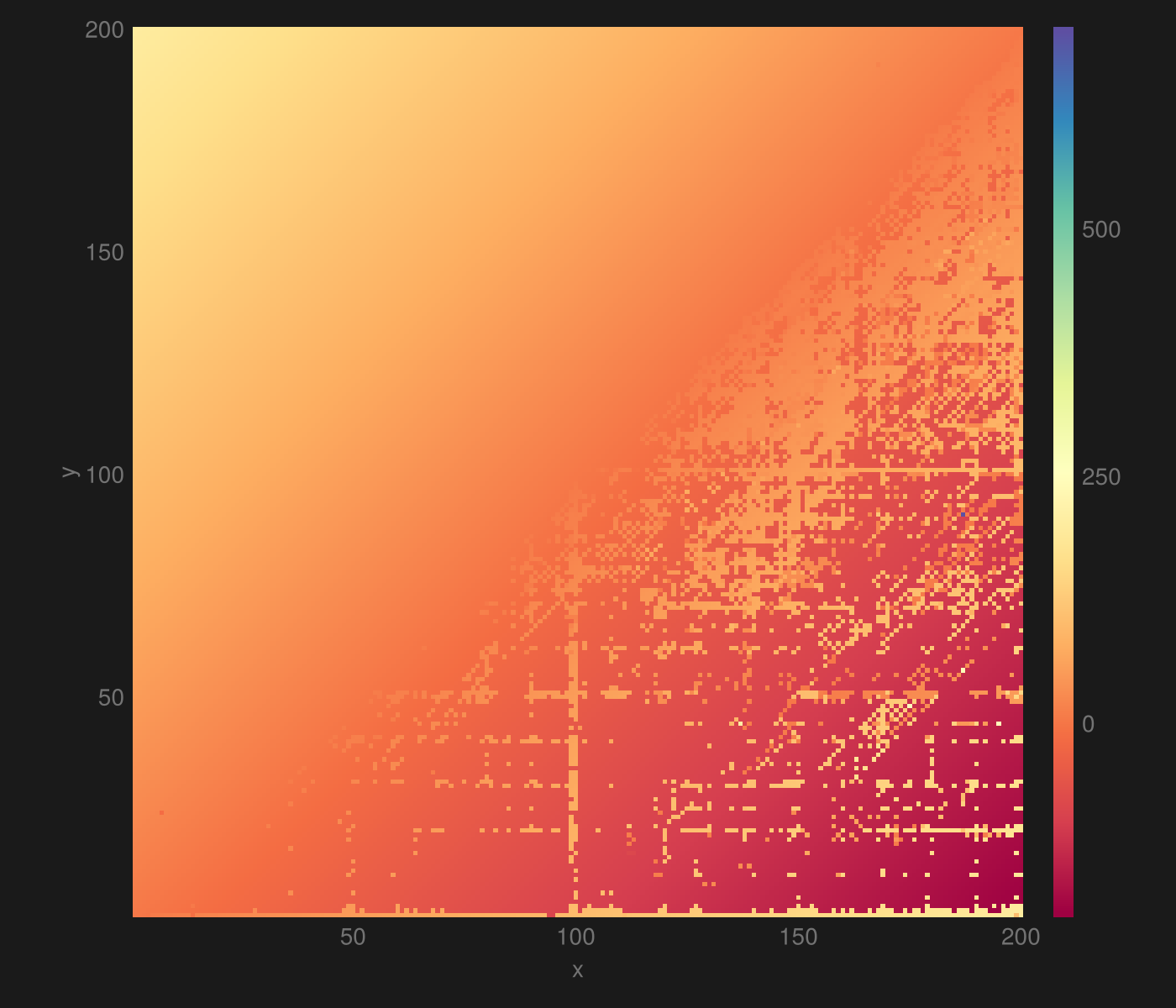 The It struggles a lot with the negative numbers but nails the positive ones.
Note the very high range of the histogram bar; there is a single extreme outlier in there, causing it, see if you can find it.
The It struggles a lot with the negative numbers but nails the positive ones.
Note the very high range of the histogram bar; there is a single extreme outlier in there, causing it, see if you can find it.
Finally :
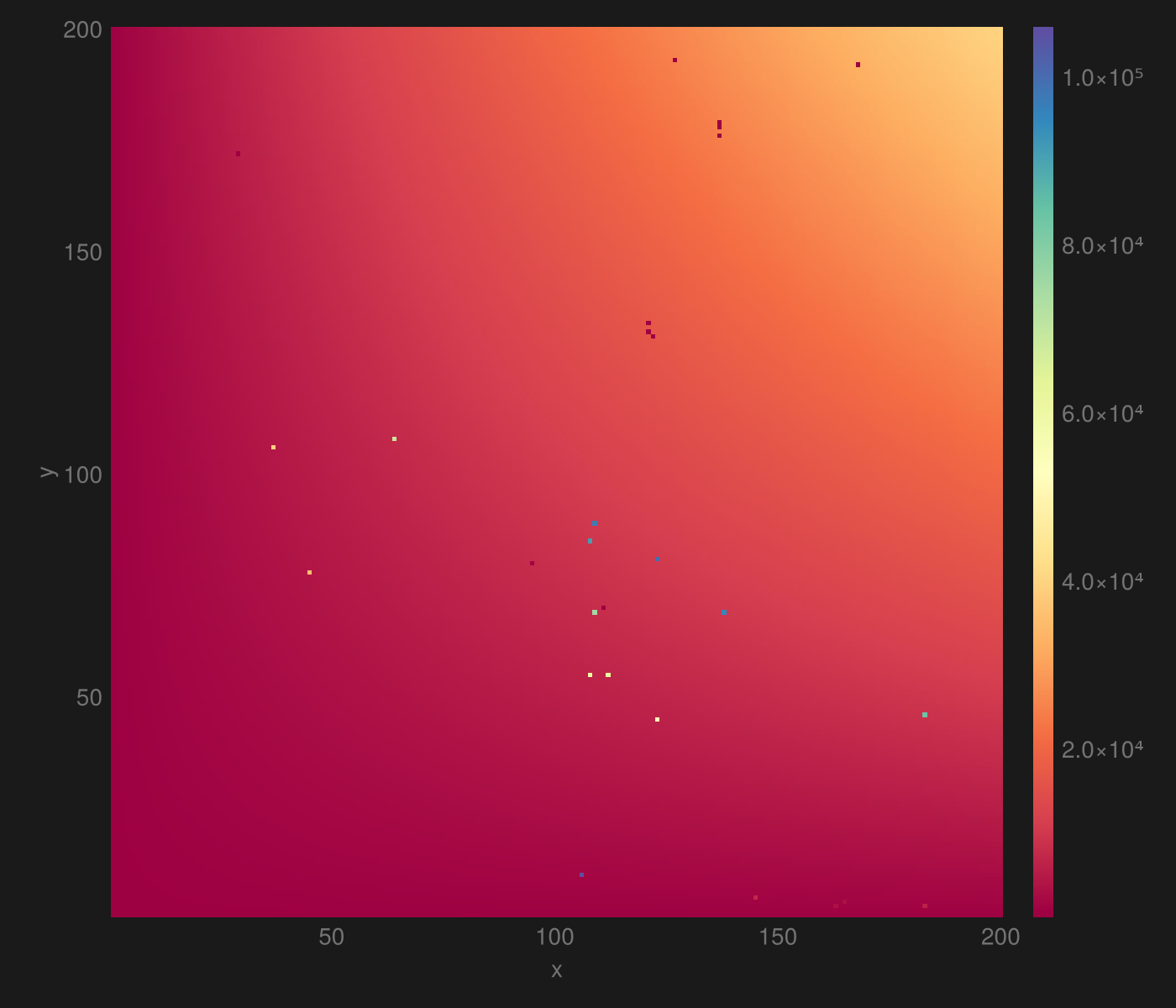
This one looks consistent but of the values are erroneous; with a lot of small mistakes like . 254 are off by 1% or more, while 32 are off by more than 10%. There are a few extreme outliers, like , which is an understandable error to make in the lexical world of LLMs.
The true origins of the idea
There is a thought experiment I ponder sometimes. What would I do if I had a practically infinitely performant computer? There are of course many interesting things to do with such a device.
One bad idea is to create an AI, using naïve brute force search. First you need an impenetrable sandbox to run the experiment within. Then you generate all C programs that are less than a trillion characters, you have limitless compute, so why not? There’s bound to be a pretty smart AI in there. Next you design a output format that’s easy to grade; a next word probability could be a good choice, similar to LLM logits. After that you filter out the programs that don’t compile, crash, take too long to respond, and don’t respond in the desired format. Then you can essentially train it like an LLM, but instead of losses and checkpoints, you get rankings for all the programs.
An interesting aspect of this method is that the primary challenge is to find anything useful among the roughly programs in the set. For perspective, if you found a way to remove 90% of the worst programs, you would need to do that two trillion times to get them down to one. The problem would likely be completely intractable, that is, no matter what you do, you would always end with a vast amount of programs tied for first place that produce nonsense when you give them something that’s not in the training data.
I still find it interesting to think of approaches to solve this supernatural problem. One training set I would use is to evaluate a large amount of arithmetic expressions. They’re easy to generate, validate, and can be made arbitrarily complex. A large subset of the programs would of course just include a calculator and be able to solve pass this test perfectly. This method would at least find that subset.
I figured that it could be interesting to try this approach with real LLMs to see how they fare. That is the true origin of this experiment.